Bộ dữ liệu machine learning là một tập hợp các instance có chung đặc điểm và thuộc tính. Nó có thể là bộ dữ liệu huấn luyện, trong đó dữ liệu được đưa vào thuật toán machine learning để huấn luyện; hoặc cũng có thể là bộ dữ liệu kiểm thử, dùng để đánh giá và kiểm tra mô hình machine learning.
Thuật toán machine learning học từ dữ liệu bằng cách nhận diện xu hướng, mối quan hệ trong dữ liệu và đưa ra dự đoán dựa trên lượng lớn dữ liệu được cung cấp. Dữ liệu huấn luyện chính xác sẽ bảo đảm hiệu suất của mô hình machine learning đạt độ chính xác cao.
Trong bài viết này, chúng tôi sẽ giới thiệu một số bộ dữ liệu công khai tốt nhất cho machine learning.
1. Bright Data
Brightdata cũng cung cấp các bộ dữ liệu công khai cho machine learning. Nền tảng này có hơn 200 bộ dữ liệu được tuyển chọn kỹ lưỡng, có thể dùng cho huấn luyện AI hoặc machine learning. Bạn không cần tự trích xuất dữ liệu nữa mà có thể dễ dàng lấy ngay các bộ dữ liệu có sẵn này. Dữ liệu hiện có bao phủ các nền tảng như Amazon, LinkedIn, Instagram, CrunchBase, Zillow Real Estate, Google Maps, X, TikTok, Facebook, Shopee, Indeed, Walmart, YouTube, Glassdoor, Shein và nhiều nền tảng khác.
Các bộ dữ liệu chất lượng cao này có dạng video, hình ảnh, âm thanh và văn bản, đồng thời được tuyển chọn kỹ lưỡng để hoàn toàn phù hợp với nhu cầu của bạn. Ngoài ra, với giải pháp của Brightdata, bạn có thể dễ dàng tìm kiếm, crawl và tương tác với web mà không phải lo bị chặn. Hệ thống của họ cũng được tối ưu để trích xuất văn bản phù hợp với LLM (mô hình ngôn ngữ lớn).
Ngoài ra, với Brightdata, bạn có thể khám phá các nguồn dữ liệu liên quan cho bất kỳ truy vấn nào, crawl trang, trích xuất nội dung và nhận đầu ra phù hợp với LLM. Việc chạy AI agent trên trình duyệt từ xa được quản lý hoàn toàn cũng rất thuận tiện. Thông qua Brightdata, bạn có thể truy cập dữ liệu có cấu trúc và phi cấu trúc hợp nhất, cũng như dữ liệu lịch sử và thời gian thực, từ đó đơn giản hóa quá trình phát triển mô hình machine learning.
Đặc điểm
Giá
2. Kaggle
Kaggle sở hữu một thư viện bộ dữ liệu công khai rất lớn, rất phù hợp cho machine learning. Bạn có thể lọc theo loại bộ dữ liệu muốn xem, như khoa học máy tính, giáo dục, phân loại, computer vision, xử lý ngôn ngữ tự nhiên (NLP), trực quan hóa dữ liệu, mô hình pre-trained và nhiều loại khác. Bạn cũng có thể chọn theo các bộ dữ liệu đang liên quan nhất hoặc phổ biến nhất hiện tại.
Website này rất chi tiết; với mỗi bộ dữ liệu, bạn đều nhận được mô tả rõ ràng để hiểu nó chứa gì, có thể đạt được mục tiêu nào với nó và ai sẽ là người hưởng lợi nhiều nhất. Ngoài ra, bạn còn có thể biết về tác giả, cộng tác viên, phạm vi bao phủ, trích dẫn và các chi tiết quan trọng khác của bộ dữ liệu.
Kaggle cung cấp các mô hình machine learning liên quan, các cuộc thi và phần thảo luận. Trong các cuộc thi, bạn có thể tạo một cuộc thi hoặc tham gia để xem liệu mình có đủ năng lực hay không. Đây là một trong những nền tảng có tính tương tác cao nhất cung cấp bộ dữ liệu công khai cho machine learning.
Đặc điểm
Giá
3. UC Irvine Machine Learning Repository
UC Irvine Machine Learning Repository là một nền tảng lý tưởng khác với nhiều bộ dữ liệu công khai phong phú và đa dạng. Bạn có thể tải xuống các bộ dữ liệu này hoặc đóng góp bộ dữ liệu của riêng mình. Với mỗi bộ dữ liệu, bạn có thể xem thông tin như đặc điểm, loại thuộc tính, lĩnh vực chủ đề, số instance, tác vụ liên quan, tính năng, bảng biến và người tạo.
Ngoài ra, sau khi đăng nhập, bạn có thể dễ dàng đánh giá bộ dữ liệu. Các bộ dữ liệu có thể ở dạng hình ảnh, đa biến, tuần tự hóa, không-thời gian, bảng, văn bản và chuỗi thời gian. Chúng bao phủ nhiều lĩnh vực học thuật như sinh học, kinh doanh, khí hậu, môi trường, kỹ thuật, game, sức khỏe và y học, luật, vật lý, hóa học và khoa học xã hội.
Ngoài ra, bạn cũng có thể lọc theo từ khóa, thuộc tính, loại dữ liệu, lĩnh vực chủ đề, tác vụ, instance, tính năng, loại thuộc tính và Python.
Đặc điểm
Giá
4. Registry of Open Data on AWS
Registry of Open Data on AWS cung cấp một danh mục giúp mọi người khám phá và chia sẻ các bộ dữ liệu có sẵn thông qua tài nguyên AWS. Nó cho phép người dùng dễ dàng thêm bộ dữ liệu vào danh mục hoặc bổ sung ví dụ về cách sử dụng bộ dữ liệu. Ngoài ra, các bộ dữ liệu được cung cấp không phải do AWS cung cấp hoặc duy trì mà đến từ bên thứ ba. Vì vậy, người dùng cần kiểm tra từng bộ dữ liệu và xác định cách sử dụng phù hợp nhất, những gì được phép, những gì không được phép và các điều khoản cấp phép liên quan.
Registry of Open Data on AWS cũng chào đón những người có dự án liên quan đến các bộ dữ liệu đã được liệt kê, để các dự án đó có thể được giới thiệu trong bài blog. Với mỗi bộ dữ liệu, bạn có thể xem thông tin về giấy phép, tần suất cập nhật, đơn vị quản lý, tài liệu, cách trích dẫn, người liên hệ, ấn phẩm, công cụ và ứng dụng, cũng như ví dụ sử dụng.
Đặc điểm
Giá
5. Microsoft Azure Open Datasets
Nếu bạn đang tìm bộ dữ liệu công khai cho machine learning, bạn cũng có thể cân nhắc Microsoft Azure Open Datasets. Bạn có thể sử dụng các bộ dữ liệu này trong quy trình machine learning và cải thiện độ chính xác của dự đoán. Ngoài ra, việc chia sẻ bộ dữ liệu với cộng đồng data scientist và developer đang ngày càng mở rộng cũng rất dễ dàng. Bạn cũng có thể tìm hiểu cách dùng open datasets để huấn luyện mô hình machine learning.
Đặc điểm
Giá
6. OpenML
OpenML là một phòng thí nghiệm machine learning toàn cầu. Nó cho phép người dùng dễ dàng truy cập nghiên cứu machine learning và tái sử dụng khi cần. OpenML là một nền tảng để người dùng chia sẻ và truy cập bộ dữ liệu, thuật toán và thí nghiệm. Tất cả bộ dữ liệu đều được chuẩn hóa định dạng và có metadata nhất quán, nên có thể dễ dàng tải trực tiếp vào môi trường làm việc yêu thích của bạn.
Ngoài ra, pipeline và mô hình có thể được chia sẻ trực tiếp từ thư viện machine learning mà bạn yêu thích. Đồng thời, việc học hỏi từ hàng triệu thí nghiệm machine learning có thể tái tạo cũng rất dễ dàng. OpenML ghi lại chính xác những bộ dữ liệu và phiên bản thư viện nào đã được sử dụng.
Là chuyên gia machine learning, bạn có thể dễ dàng chia sẻ công việc của mình; chủ sở hữu dữ liệu có thể chia sẻ dữ liệu để tạo thử thách và hợp tác với cộng đồng machine learning; nhà phát triển thuật toán có thể tích hợp công cụ của bạn với OpenML để dễ dàng nhập và xuất dữ liệu cũng như thí nghiệm.
Đặc điểm
Giá
7. Sigma AI open datasets

Sigma AI Open Datasets cung cấp một loạt bộ dữ liệu miễn phí, mã nguồn mở mà bạn có thể dùng cho các thí nghiệm và dự án machine learning. Khi liên hệ với họ, bạn cũng có thể tự do thêm các bộ dữ liệu công khai dùng cho machine learning vào cơ sở dữ liệu.
Việc tìm bộ dữ liệu trên nền tảng này không phức tạp; bạn chỉ cần nhấp vào một mục, lọc theo nhiều Thông số khác nhau và tìm kiếm bộ dữ liệu dựa trên một từ hoặc cụm từ. Sau đó, chỉ cần tải file CSV ở góc dưới bên phải.
Đặc điểm
Giá
8. Allen AI Open datasets for machine learning
AllenAI có một cơ sở dữ liệu bộ dữ liệu công khai rất lớn, có thể dùng để huấn luyện AI và machine learning. Bằng cách truy cập các dữ liệu này, người dùng có thể hiểu cách các mô hình tốt nhất hoạt động và cách cải thiện chúng để trở nên hữu ích hơn.
May mắn là tất cả bộ dữ liệu đều được thu thập theo cách có đạo đức và có thể sử dụng an toàn. Trên nền tảng Hugging Face, bạn có thể xem cách bộ dữ liệu được thu thập cũng như các thành viên trong nhóm. Bạn có thể duyệt để xem các cập nhật mới nhất và truy cập bộ dữ liệu theo chủ đề mình quan tâm.
AllenAI cung cấp mô hình ngôn ngữ, mô hình đa phương thức, framework đánh giá và open datasets. Sự đa dạng này khiến đây trở thành lựa chọn ưu tiên của nhiều người. Một số bộ dữ liệu gồm có WildChat, S2ORC, Self-instruct, Kiwi, Chime, Drop, Qasper và nhiều bộ khác.
Đặc điểm
Giá
9. Data Gov Open Data
Data.gov có hơn 318.500 bộ dữ liệu khả dụng. Bạn có thể lọc theo số lượt xem nhiều nhất, mới thêm gần đây, bộ dữ liệu theo tổ chức hoặc dữ liệu địa không gian. Nhờ các nhóm phân loại này, bạn có thể dễ dàng tìm thấy bộ dữ liệu mình cần. Data.gov là một trung tâm dữ liệu tài nguyên của Hoa Kỳ, ra mắt năm 2009, ban đầu chỉ có 47 bộ dữ liệu, và theo thời gian đã tăng lên hơn 300.000 bộ.
Mục tiêu chính của website dữ liệu mở này là bảo đảm những dữ liệu giá trị đó dễ tiếp cận. Nó bao phủ nhiều danh mục như chính quyền địa phương, khí hậu, người cao tuổi, năng lượng, Bắc Cực, tài nguyên nước, sức khỏe con người, hệ sinh thái, giao thông, khả năng chống chịu lương thực và nhiều lĩnh vực khác. Bạn có thể dùng các dữ liệu này để nghiên cứu, phát triển ứng dụng web và di động, thiết kế trực quan hóa dữ liệu và hơn thế nữa.
Đặc điểm
Giá
10. Datarade.Ai
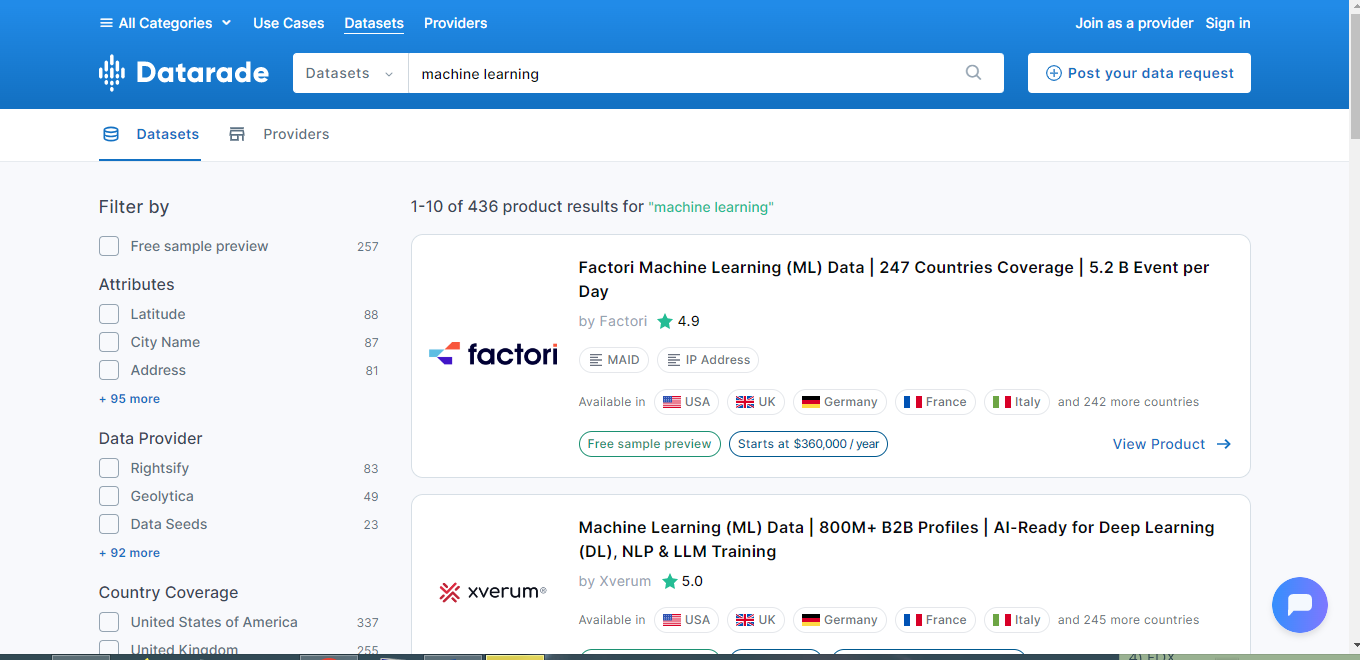
Datarade.ai là một nền tảng khác để lấy bộ dữ liệu công khai dùng cho machine learning hoặc huấn luyện AI. Điều này hoàn toàn phụ thuộc vào loại dữ liệu bạn muốn thu thập. Nền tảng này có thanh tìm kiếm trực quan, cho phép bạn tìm bất kỳ loại bộ dữ liệu nào mình cần, chẳng hạn như machine learning datasets. Mỗi bộ dữ liệu đều có phần xem trước mẫu miễn phí, cho phép người dùng kiểm tra nội dung trước khi mua.
Bạn có thể dễ dàng lọc theo các tiêu chí như mẫu miễn phí, thuộc tính, nhà cung cấp dữ liệu, phạm vi phủ quốc gia, danh mục và phương thức giao hàng. Bạn có thể nhận bộ dữ liệu qua S3 bucket, email, SFTP, REST API, xuất UI, Feed API, SOAP API, streaming API, file nén, Azure Blob Storage, Google Cloud Storage, Google BigQuery, chia sẻ Snowflake, chia sẻ Databricks Delta, FIX API, WebSocket và nhiều hình thức khác.
Đặc điểm
Giá
11. Meta AI
Meta AI cũng cung cấp nhiều bộ dữ liệu và benchmark để huấn luyện, đánh giá và kiểm thử các mô hình AI và machine learning, nhằm thúc đẩy tiến bộ trong các lĩnh vực liên quan. Các loại dữ liệu của họ rất đa dạng, bao gồm FACET, Ego TV Dataset, MMCSG Dataset, Speech Fairness Dataset, Everyday Conversations, Common Objects in 3D, Segment Anything, DISC21 Dataset, Ego Objects Dataset, Flores benchmark dataset, Ego4d và nhiều hơn nữa. Việc chọn bộ nào phụ thuộc vào công việc bạn đang làm và nguồn lực bạn cần.
Đặc điểm
Giá
Kết thúc
Phần lớn các nguồn dữ liệu machine learning cung cấp dữ liệu phong phú và đa dạng, vì vậy bạn có thể dễ dàng lấy dữ liệu mình cần theo thời gian thực. Các dữ liệu này chủ yếu đến từ nhiều lĩnh vực và ngành nghề khác nhau, từ đó tạo ra nhiều biến số đa dạng.
Ngoài ra, hầu hết các website cung cấp bộ dữ liệu công khai cho machine learning đều rất thân thiện với người dùng, giúp người dùng, developer và nhà nghiên cứu dễ dàng tìm thấy nội dung họ cần. Phần lớn các website cũng cung cấp hỗ trợ cộng đồng, nơi mọi người có thể tham gia thảo luận, học hỏi từ kinh nghiệm của người khác và nhận trợ giúp cho dự án.


